Application of Microblog Data Mining Based on k-means Algorithm
Published:
This project used a web crawler to collect a certain range of data. Natural language processing (NLP) techniques were employed for embedding the raw data, making it fit the k-means clustering algorithm. To enhance the clustering performance, a user feature model was constructed by the principal component analysis (PCA). The project applied the k-means clustering algorithm to categorize user data effectively
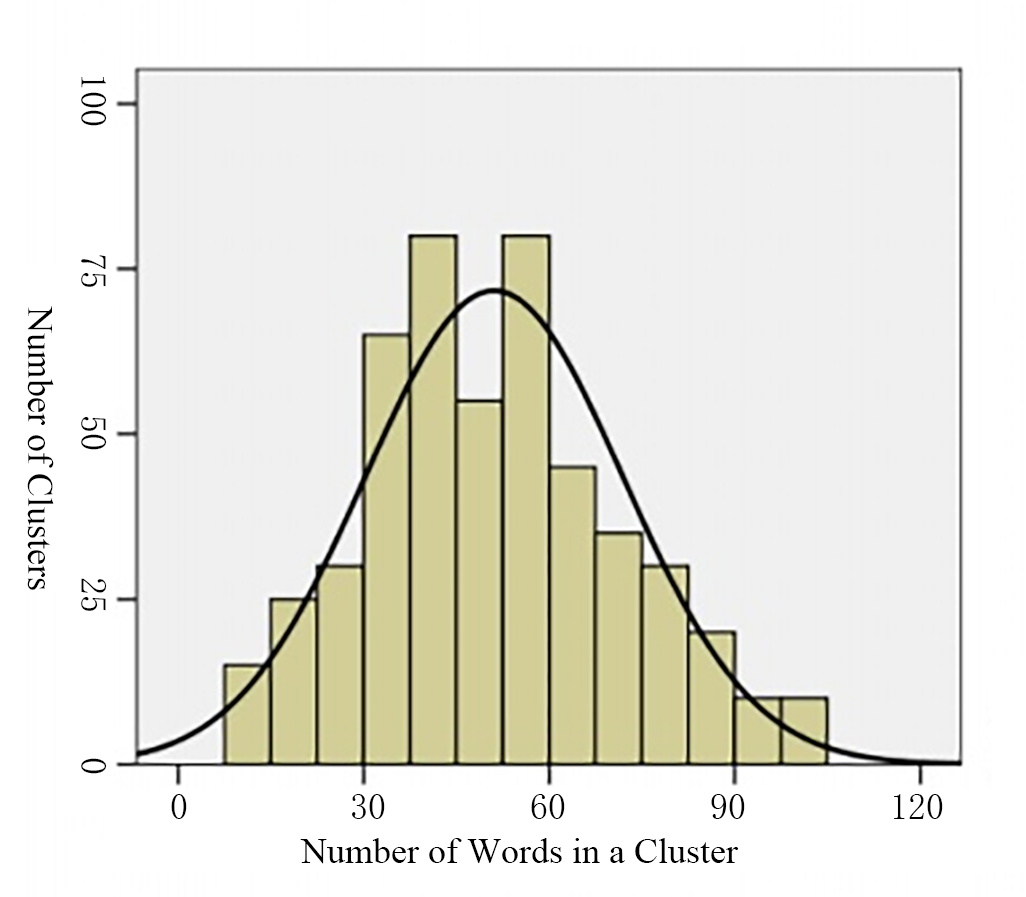
Distribution of K-mesns clusters
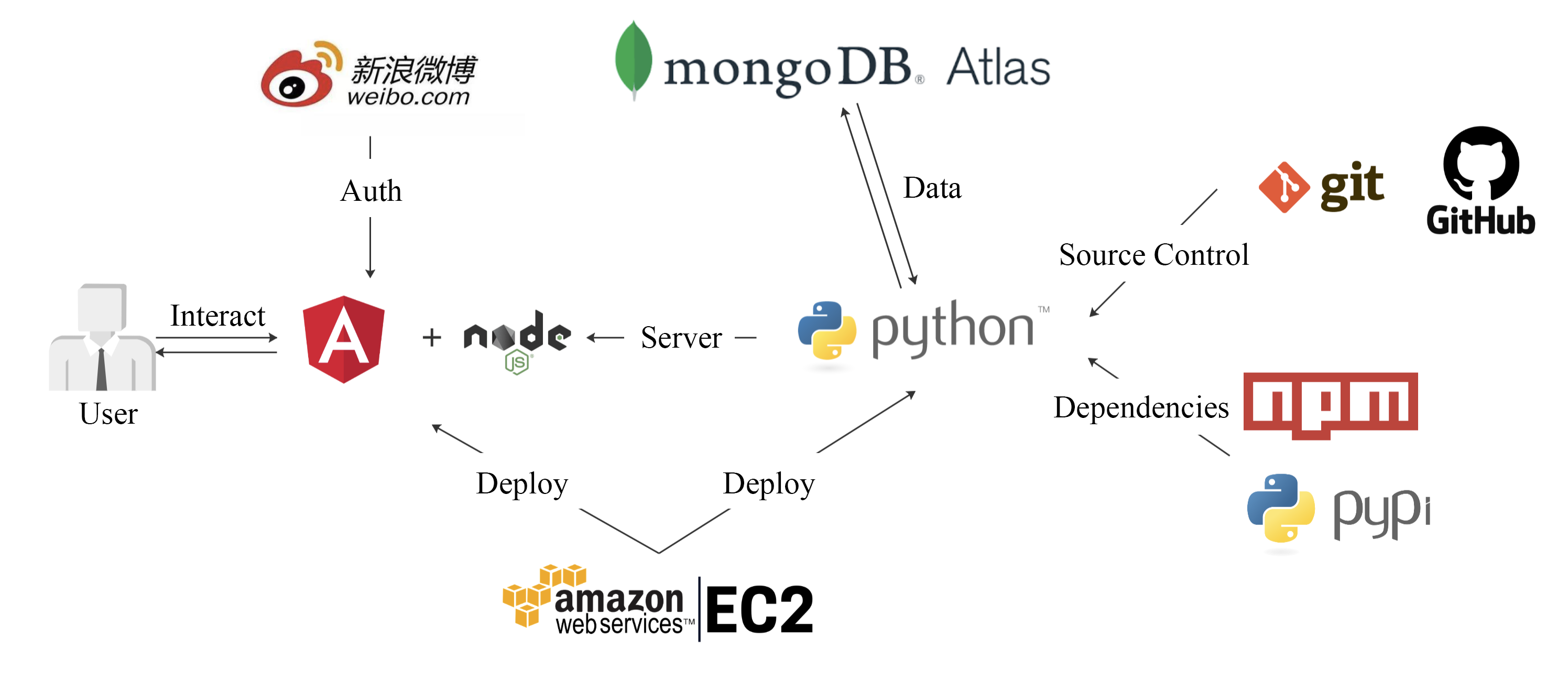
Flow chart of whole project
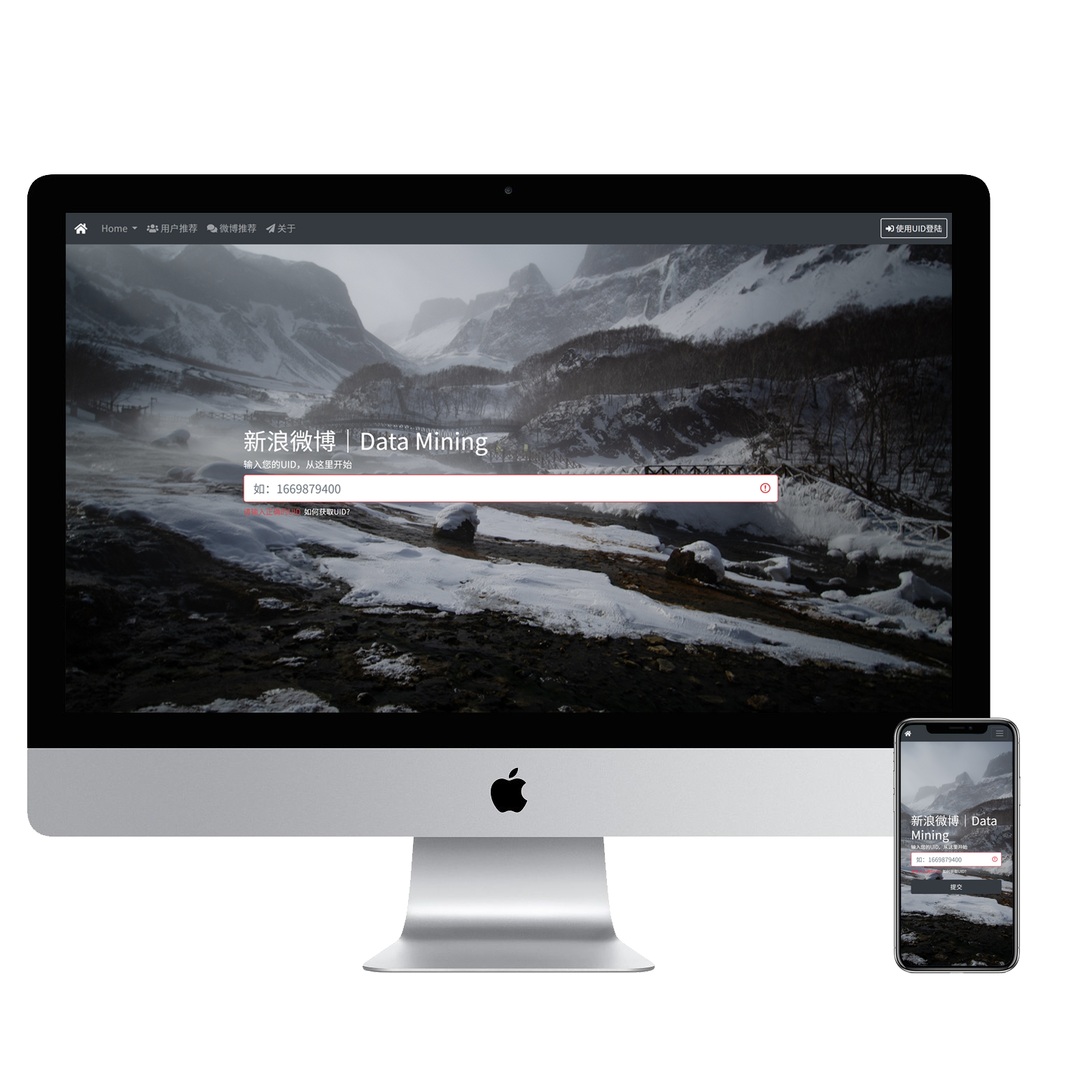
User Interface